

Another day, another update.
More troubleshooting was done today. What did we do:
- Yesterday evening @phiresky@phiresky@lemmy.world did some SQL troubleshooting with some of the lemmy.world admins. After that, phiresky submitted some PRs to github.
- @cetra3@lemmy.ml created a docker image containing 3PR’s: Disable retry queue, Get follower Inbox Fix, Admin Index Fix
- We started using this image, and saw a big drop in CPU usage and disk load.
- We saw thousands of errors per minute in the nginx log for old clients trying to access the websockets (which were removed in 0.18), so we added a
return 404in nginx conf for/api/v3/ws. - We updated lemmy-ui from RC7 to RC10 which fixed a lot, among which the issue with replying to DMs
- We found that the many 502-errors were caused by an issue in Lemmy/markdown-it.actix or whatever, causing nginx to temporarily mark an upstream to be dead. As a workaround we can either 1.) Only use 1 container or 2.) set
proxy_next_upstream timeout;max_fails=5in nginx.
Currently we’re running with 1 lemmy container, so the 502-errors are completely gone so far, and because of the fixes in the Lemmy code everything seems to be running smooth. If needed we could spin up a second lemmy container using the proxy_next_upstream timeout;max_fails=5 workaround but for now it seems to hold with 1.
Thanks to @phiresky@lemmy.world , @cetra3@lemmy.ml , @stanford@discuss.as200950.com, @db0@lemmy.dbzer0.com , @jelloeater85@lemmy.world , @TragicNotCute@lemmy.world for their help!
And not to forget, thanks to @nutomic@lemmy.ml and @dessalines@lemmy.ml for their continuing hard work on Lemmy!
And thank you all for your patience, we’ll keep working on it!
Oh, and as bonus, an image (thanks Phiresky!) of the change in bandwidth after implementing the new Lemmy docker image with the PRs.
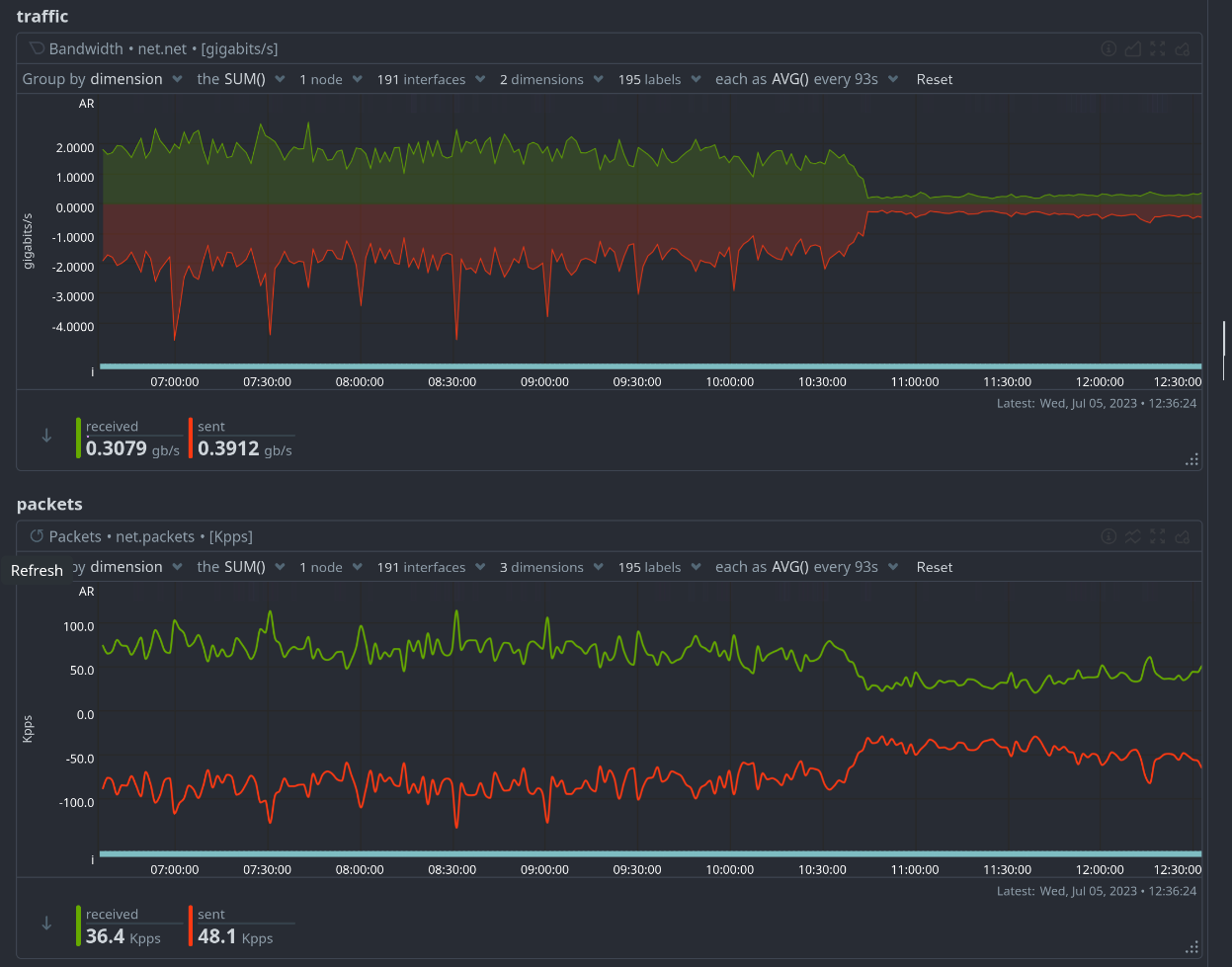
Edit So as soon as the US folks wake up (hi!) we seem to need the second Lemmy container for performance. So that’s now started, and I noticed the proxy_next_upstream timeout setting didn’t work (or I didn’t set it properly) so I used max_fails=5 for each upstream, that does actually work.
You guys had better quit it with all this amazing transparency or it’s going to completely ruin every other service for me. Seriously though amazing work and amazing communication.
server load is too low, everyone upvote more stuff so i can optimize more
edit: guess there is some more work to be done 😁
Upvote causes an endless spinner on Liftoff. 😁
I’m getting 504 gateway time outs when I try to upvote
For me it works way better than before
seems like it may have been a temporary issue. It’s clearing back up.
It doesn’t for me actually. Maybe just on Lemmy.world?
I don’t understand your graph. It says you are measuring gigabit/sec but shouldn’t the true performance rating be gigabeans/sec for a Lemmy instance?
deleted by creator
And where’s the statistics for days between each core dump? A healthy instance should have at least three days between each one
Depends on whether they have fiber or not.
I see what you did there.
I’m on another instance, but here’s some federated activity for you.
deleted by creator
Web-ui is very smooth rn… is this .world?
😅
Joke aside, the improvement is like heaven and earth. Love it!. Good work teams!Double the image upload size and you will see more shitposts
I was gonna argue that you’d see more bean posts, but at this point they’re the same thing, both in the pun sense and the literal sense
aye aye sir, to the upvote machine!
I’m not sure wtf you just said, but lemmy.world feels very smooth today, so thank you for your continued hard work!
Test:
Upvote if you can see this comment. 👍
Looking good from here.
Edit: And comment rapidly going through. :)
I can see and upvote this comment. 👍
I can also see and updoot yours. 👍
502, sorry mate.
Damn, better luck next time.
Shame you’re getting no karma. Take my upvote.
I think i was on r for a year or two before I learned what karma was. I still don’t understand it’s value.
Oh, I thought that was the joke 😅
Like a tongue-in-cheek, remember our silly old Reddit ways kinda thing.
Ha. I don’t miss it. I upvote for good content.
Appreciate that these updates use the yyyy-mm-dd format :D
ISO-8601. The only correct format!
'Tis the superior format 😤
ISO 8601 all the way baby!
Hell yeah. I use YYYY.MM.DD_HH:MM:SS in my filesystem, for screenshots etc, so alphabetical is chronological. :)
It’s so smooth now; the speed difference is insane! You all are doing excellent work!
Even though i’m not from this instance, this is such a nice way of keeping the users posted about changes. I wish more companies (I know this is not a company) went straight to the point, instead of using vague terms like “improved stability, fixed few issues with an update” when things are changed. I hope all instance owners follow this trend.
The owner of your instance has been a big help. You’ve also chosen a good instance!
@sunaurus@lemm.ee is awesome. He keep us aware of what’s happening, planned maintenance hours, etc. His commits on making lemmy scale horizontally is what kept lemm.ee snappy even when we had a huge influx of users. I hope Lemmy as a whole continues this ethos of collaboration.
As an IT support person, I’ve learnt to dumb things down for management. They don’t want to hear stuff like “Increased the SGA, changed the buffer size and added a function based index…etc”. Sometimes I’ll do a short and a long version something like “the issue was around memory settings which have been increased”, plus the detailed info.

The change is noticeable. Good job guys.
Thanks for the updates.
I agree. Felt it immediately when I started browsing. Everything is faster and more responsive, on top of the error messages disappearing
Yup I can even post comments first try, without getting an error! Things are working well!
Really noticeable. Cool update. Thank you, guys! ❤️
I’m very curious: does single Lemmy instance have the ability to horizontally scale to multiple machines? You can only get so big of a machine. You did mention a second container, so that would suggest that the Lemmy software is able to do so, but I’m curious if I’m reading that right.
A single instance, no. You run multiple instances on multiple machines, then put a frontend (nginx in this case) to distribute the traffic among them.
Interesting, how does that actually work then? Are they just sharing the same database? Is that a supported configuration?
They would all have to share a database, although I don’t see why there would be any issues.
The database software they’re using can fairly comfortably handle multiple changes at once, although it might get a bit funny if a user is split between multiple instances.
Usually in such cases you would need sticky sessions, i.e. a user always stays at the same frontend.
If you want to get really fancy, could do some distributed session management with something like redis. Though the underlying application needs to be abstracted out already to allow for it.
How great is it to be a part of history in the making -
This is Web 3 in its fomenting -
Headlines ~5yrs:
The ending of Web 2 was unceremonious and just ugly. u/spez and moron@musk watched as their social media networks signaled the end of Web 2 and slowly dissolved. Blu bird’s value disintegrated and Reddit’s hopes for IPO did likewise. Twitter and Reddit dissolved into odorous flatulence as centralization fell apart to the world’s benefit. Decentralized/federated social media such as Mastodon and Lemmy made their convoluted progress and led Web 3’s development and growth…
This is how history is made, it’s ugly and convoluted but comes out sweeet…
Is it safe to use 2FA yet?
It doesn’t really work I think. Havent tested yet.
Thanks for the feedback, I’ll hold for now!
I couldn’t get it to work.
I was able to enable it and add the code to my authenticator but it would not accept a login with the 2FA code.
Fortunately I was still logged in elsewhere to disable 2FA again or I may have gotten locked out
It’s always been safe to use 2FA if your authenticator app supports SHA256. Unfortunately, it turns out that a lot don’t. The only solutions are going to be Lemmy switching to SHA1 or users switching to auth apps that support SHA256. I think the first is more likely to happen than the second.
I suppose Authy doesn’t yet support SHA256? :/
I believe that is correct, from what I’m reading. I think Lemmy is probably going to switch to SHA1 as the default. Research has shown that it’s basically as safe to use for 2FA as SHA256 and SHA512 and obviously it has universal compatibility per the spec. The spec only lists SHA256 & 512 as allowed alternatives, not required for full adherence to the spec. I imagine Lemmy will change it so that SHA1 is the default option with maybe an option to still do SHA256 with some well explained warnings.
From what I’ve researched you’re 100% correct.
The main problem is that even though Authy doesn’t support SHA256, Lemmy still enables 2FA. Lemmy doesn’t ask for an auth token before enabling 2FA nor generates any backup codes. The user is prompted with success but will be locked out on of the account on sign out. Not good.
just tried it and it works
Awesome work - things seem to be running much more smoothly today.
Do you have anything behind CDN by chance? Looking at the lemmy.world IPs, the server appears to be hosted in Europe and web traffic goes directly there? IPv4 apparently seems to be resolving to a Finland-based address, and IPv6 apparently seems to be resolving to a Germany-based address.
If you put the site behind a CDN, it should significantly reduce your bandwidth requirements and greatly drop the number of requests that need to hit the origin server. CDNs would also make content load faster for people in other parts of the world. I’m in New Zealand, for example, and I’m seeing 300-350 ms latency to lemmy.world currently. If static content such as images could be served via CDN, that would make for a much snappier browsing experience.
Yes that’s one of the things on our To Do list
We use Cloudflare at work. It’s been invaluable so far.
+1 for Cloudflare. Use their service in my homelab
Excellent! Thank you for the hard work and transparency. It’s great to see.
Shouldn’t the correct HTTP status code for a removed API be 410? 404 indicates the domain wasn’t found or doesn’t exist, 410 indicates a resource being removed
Or 418 for the wrong API being used :^)
Unless one is attempting to brew tea.
Aren’t we always trying to brew tea?
Gadzooks! These are huge fixes. Compliments to the team, you guys pulled off a small miracle today.























